Common Errors#
Access Denied or Too Many Requests#
First, make sure that your url is accessible.
If it requires username and password then set them accordingly in httpUsername and httpPassword parameters and try again.
If you use Google Docs/Google Drive, make sure that the link to a file or a document is not requiring login. Try to copy the link and open it in Incognito Mode in the browser to see whether it opens as expected.
If you are getting Too Many Requests (or sometimes Access Denied from Google Drive/Docs/Sheets), then try to add caching for the input file. To enable caching please insert cache: before the link.
Example:
Without caching:
https://example.com/file1.pdfWith caching:
cache:[https://example.com/file1.pdf](https://example.com/file1.pdf)
NOTE: Caching will not fetch the original file but will cache it in PDF.co and reuse the file for the next 24 hours without making a request to the original url.
ECONNREFUSED error#
An error message containing ECONNREFUSED represents a connection problem. This error is rare, as we have taken measures such as increasing server scalability.
If the error ECONNREFUSED is occurring frequently, you should implement 2-3 retries in your code. The connection error may also be caused by your ISP, temporary issues with routers and many other things. TCP/IP connection is not guaranteed, so any temporary issues with the local ISP, routers, DNS providers may affect connectivity. Zapier and Make have built-in retries.
Error 400 bad request#
The error 400 means incorrect parameters. Please go to your API Logs for more information on which request and what is causing the error https://app.pdf.co/account/logs/api.
Feel free to contact our support team at support@pdf.co if you need help in troubleshooting. Please enable access to your API Logs so our developers can review them.
Error 403, Can’t download file, Input document is damaged, or Login page is converted instead of the file content#
Applies to the following errors:
Error 403
Can’t download file
Input document is damaged or of incorrect type
See a login page instead of the file content
Invalid url
If you get any of the error messages above, here are some ways to resolve them:
Check input link to make sure it is publicly accessible. The PDF.co API engine requires the source file to be publicly accessible in order to process it. If you are using Google Drive, Dropbox or similar cloud storage services, change the file permission to
Anyone with the linkto make it public.Check input file to make sure it is the correct file format. An incompatible source file type can result in
input document is damagedorof incorrect typeerrors. For example, if you are merging PDF and non-PDF files, please use the correct PDF Merger endpoint.Add the cache: prefix. Frequent access to a file may result in restricted access by services like Google, Dropbox and similar. Try to add
cache:before the URL to resolve the problem. The new URL will look like this:cache:[https://url.com/randomurl.](https://url.com/randomurl.)Check input link to make sure it is valid. If an incorrect or incompatible link is passed to the API, it will result in an
Invalid urlerror.
If the above steps do not resolve the issue, please enable access to your API Logs and reach out to our support team at support@pdf.co for assistance. To grant our support team access to your API Logs, refer to this guide: https://pdf.co/enable-api-logs-access.
Error 448 webpage not found#
The error response 448 represents an invalid input URL. This error is mostly observed in the url to pdf endpoint when the input URL is invalid or not accessible.
For example, when pdf from url is executed with the invalid URL https://abcdefabcdef/testing it will return an error.
Request:
curl --location --request POST 'https://api.pdf.co/v1/pdf/convert/from/url' \
--header 'x-api-key: YOUR_PDFCO_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{
"url": "https://abcdefabcdef/testing"
}'
Response:
{
"error": true,
"status": 448,
"message": "Web page not found",
"credits": 0,
"duration": 8133,
"errorCode": 448
}
Fatal error: Uncaught ValueError: Path cannot be empty#
When you get the error message Fatal error: Uncaught ValueError: Path cannot be empty, please apply the following changes to the php.ini file and the html file.
Modify the php.ini file with the following.
max_execution_time=300
memory_limit=1024M
post_max_size=4000M
upload_max_filesize=4000M
And in the HTML file modify "MAX_FILE_SIZE" to the following.
<input type="hidden" name="MAX_FILE_SIZE" value="8000000000"/>
Google Docs or Google Drive error with Too Many Requests, Access Denied, or Can’t download file#
Sometimes if you use Google Drive, Google Docs, Google Sheets, Dropbox, or similar free cloud storage services to store your input files, you may receive Too Many Requests, Access Denied or Can't download file errors after previously successful calls. Cloud services are throttling requests to prevent frequent access to their files by using this type of protection. Paid plans like Google Workspace provide better support for frequent access, but still throttle all incoming requests.
To solve this issue, PDF.co can use its built-in secure input url cache. Just add the cache: prefix to your input url to enable caching.
For example: cache:[https://example.com/file.pdf](https://example.com/file.pdf)
This will tell PDF.co to cache the file from the url for 24 hours. Instead of re-requesting your url every time, it will use its cached version. This will prevent the Too Many Requests error.
As an alternative, you can store your input files in our built-in file storage, which was specifically designed for providing an alternative and more reliable way to store files for re-use in PDF.co. It is available at https://app.pdf.co/files. You can upload your file and copy the special link to it (so called token), that looks like filetoken://12345… This type of link can be used from the PDF.co platform only.
To learn more about PDF.co built-in file storage, please visit this page https://pdf.co/how-to-use-file-storage-on-pdfco.
Applies to the following errors:
error 403can't download filetoo many requestsaccess denied
Google Drive Source File Error 442#
The error message Error 442 or input document is damaged occurs in two scenarios: (1) when the source file is not in the expected file format, or (2) when the file is prevented from being downloaded. In the first scenario, please verify whether you are using the supported file format. In the second scenario, this issue often arises when a Google Drive file cannot undergo virus scanning. This keeps the PDF.co engine from accessing the actual file.
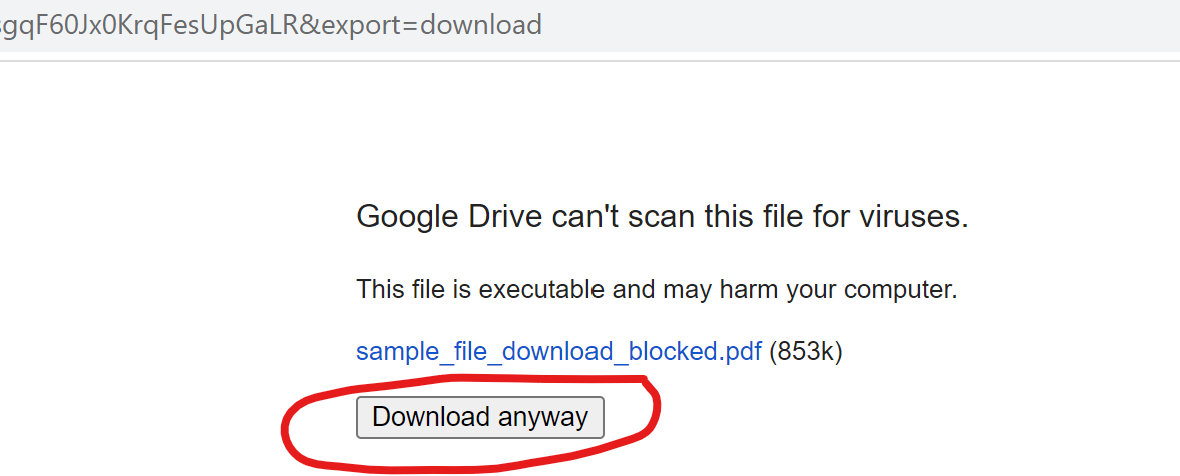
To verify whether this applies to your file, please use the following link format and replace file_id with your actual file ID:
https://drive.google.com/uc?id=file_id&export=download
To resolve this issue, you have two options: either use a Google API Key or an authorization access token from Google OAuth.
Below, you will find a step-by-step guide on generating your Google API Key:
Important: To ensure the security of your Google API Key within PDF.co, follow these instructions to enable Strict Mode for API Logs: https://app.pdf.co/account/logs/api. Enabling Strict Mode will conceal the source file URL, which contains your Google API Key. It is recommended to enable Strict Mode whenever sensitive data, such as a Google API Key, is present in the source file URL.
Start by creating a Project at https://console.cloud.google.com.
Navigate to the “APIs & Services” section.
Click on “Enabled APIs and Services” option.
Click on “+ Enable APIs and Services.”
Search for the Google Drive API.
Enable the Google Drive API.
Go to the “Credentials” section.
Click on “+ Create Credentials.”
Choose “API Key.”
After creating your API Key, hover over the warning icon next to its name and click on “Edit Settings.”
Configure your API Restrictions. For this demo, select the “Restrict API” radio button and choose the Google Drive API. Please setup the restrictions according to your needs. You may also contact Google Support for assistance.
Click “Save.”
You are now prepared to use your Google API Key. Copy the following URL format and replace file_id with your actual file ID, and api_key with your Google API Key. Use this modified URL as your source file link, allowing you to download the previously blocked file:
https://www.googleapis.com/drive/v3/files/file_id/?key=api_key&alt=media
NOTE: Please reach out to Google Support for guidance on how to ensure the security of your Google API Key.
To use the authorization access token from Google OAuth instead of the Google API Key, please start here https://developers.google.com/identity/protocols/oauth2.
Make maximum number of repeats exceeded#
This error originates from Make.com. Make.com has a 5-minute limitation for every module on their platform.
To fix this issue, you need to add a delay and another step to check the job status. Set a delay time that best suits the time it needs to process the job.
NoSuchKey The specified key does not exist error#
If you enable async mode and attempt to access the output while the job is still processing, you may encounter the NoSuchKey error indicating that the specified key does not exist.
To resolve this issue, include a background job check in your code to monitor the job status. You can find our code samples in managing background jobs here.
Or you can also use our code samples which include async and background job checks here.
Postman Collection
If you are using Postman Collection and have set async to true, the result will provide a jobId. Use this jobId to check the job status through the Background Jobs Check available in the Postman collection.
For further details regarding background job checks, please refer to our API Docs.
Zapier/Make
Automation solutions like Zapier and Make have a timeout limit of 30 seconds to 5 minutes. However, we can overcome this limitation by introducing a delay in your workflow. By introducing a delay in your workflow, you can prevent the timeout error and effectively process large files using automation solutions.
PDF.co response links are broken#
After 15 June 2022 to improve the security of the platform, output links will become much longer by default. New links are longer but provide additional layer of the security.
Please review the information below to make sure that your app or integration will continue to run properly after this change.
Note: If you use Zapier, Make, UiPath, or another plugin then in most cases you won’t notice this change.
Old - highly randomized output link (with encrypt=false, up to 150 characters in most cases):
https:// pdf-temp-files.s3.us-west-2.amazonaws.com/AVOAW8SKCG2KO8X8Y7HTFSRZRYPLCNZ2/result.pdf
New - highly randomized and signed output link (2,000+ chars length, equal to encrypt=true):
https:// pdf-temp-files.s3.us-west-2.amazonaws.com/AVOAW8SKCG2KO8X8Y7HTFSRZRYPLCNZ2/result.pdf?X-Amz-Expires=3600&X-Amz-Security-Token=FwoGZXIvYXdzEHMaDL61FzxjG0uSGVGBlSKBAaTI5leR6n0GpK7rZPnqDsuMCX7jj6T%2FfMqMhRjlXGTHk1NWNARHt%2
B%2B6IZXjwmT%2FsH3deSLD%2FDLU4p4P6JLQk68Fn%2BHmnPX%2F3rQWU0iLiYpyGUDksjXzgI%2B2dymSr7UyF2IIsKOh3F9uwQCM
s8TsQz9GQoM5wBNblZ%2FSp7nvw8N1FSjZiOKUBjIoTIWor5F7AmClCtMLw%2BL7TfF9dOB3DPCgZkKAaTJ4AkTd7wWjTkP23A%3D%3D&X
Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIA4NRRSZPHOWNDWVHG/20220602/us-west-2/s3/aws4_request&X-Amz
Date=20220602T093521Z&X-Amz-SignedHeaders=host&X-Amz-Signature=f2e384b056bdd5a6c1afd91c1d6961b11a9751e02980e986392b19985b6cd815
You can test new long links by setting the encrypt parameter to true in your app or script. New long links are similar to having encrypt parameter always set to true.
Why did we need to change this?
Signed links provide an additional layer of protection, new embedded signatures for links are powered by a SHA 256-bit algorithm, and an Amazon AWS powered security mechanism for links expiration.
Expiration for output links can be controlled more precisely, up to 1 minute (for example, you can set
expiration=1to expire output link in just 1 minute).
Other common reasons for broken output links#
Link is accessed after the expiration period
By default, PDF.co response links are accessible for 1 hour. After that duration, the file is removed from the PDF.co cloud and links are expired.
However, you can adjust expiration parameters on request as required.
Async Job is created and the success status is not checked
All PDF.co requests can be executed in asynchronous mode by setting async parameter value to true. This asynchronous request returns a jobId as well as an output URL in response.
This URL won’t be ready and publicly accessible unless the job is checked by job/check request and it has success status.
API response does not pass through JSON parser/decoder
Most of the request clients have a built-in JSON parser/decoder. For security reasons, the PDF.co response by default contains the encrypted file url link this:
{
"url": "https://pdf-temp-files.s3.us-west-2.amazonaws.com/D0VXAHON7B4WALKOVR2NIUM2ERRPPYI3/sample2.pdf?X-Amz-Expires=3600&X-Amz-Security-Token=FwoGZXIvYXdzEK%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDEbAXxnsfmdl03uy1SKCAR%2B1xIlLYex45jB2WWJvynVJZ8l3dQWfQEmMxKIJJWsBexPViHm8HHD5X6zxCTaw7kmtJjfiKwp6QclRO%2BGa9%2B5VYLWEVP5n88%2B1YPeGwHVkD%2F%2FtUUdJ7jZuFJ6TUurGS%2FIdklxFnC2c9XBcEUunp5bnf5PuNLde38SnndtuCK%2B%2B9UAo6bqIlwYyKBbUA7YQZAFVN6XkG%2ByGzjmvq1UI149EBOdhilHaR6EaZlMYnfV1V4s%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIA4NRRSZPHPS55AP5S/20220728/us-west-2/s3/aws4_request&X-Amz-Date=20220728T053316Z&X-Amz-SignedHeaders=host&X-Amz-Signature=0c16c754e310e8229f0b5a31f928cc6e432b53ed7d9957dd59b23d4b187c9dfd",
For most scenarios, this URL will be accessible without issue as it will pass through the JSON parser/decoder.
However, when a request is made by clients which do not have a built-in JSON parser/decoder (example cURL), it will show a raw response and the user might be confused with a link appearing as broken.
For example, a cURL response would resemble the following:
{"url":"https://pdf-temp-files.s3.us-west-2.amazonaws.com/D0VXAHON7B4WALKOVR2NIUM2ERRPPYI3/sample2.pdf?X-Amz-Expires=3600\u0026X-Amz-Security-Token=FwoGZXIvYXdzEK%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDEbAXxnsfmdl03uy1SKCAR%2B1xIlLYex45jB2WWJvynVJZ8l3dQWfQEmMxKIJJWsBexPViHm8HHD5X6zxCTaw7kmtJjfiKwp6QclRO%2BGa9%2B5VYLWEVP5n88%2B1YPeGwHVkD%2F%2FtUUdJ7jZuFJ6TUurGS%2FIdklxFnC2c9XBcEUunp5bnf5PuNLde38SnndtuCK%2B%2B9UAo6bqIlwYyKBbUA7YQZAFVN6XkG%2ByGzjmvq1UI149EBOdhilHaR6EaZlMYnfV1V4s%3D\u0026X-Amz-Algorithm=AWS4-HMAC-SHA256\u0026X-Amz-Credential=ASIA4NRRSZPHPS55AP5S/20220728/us-west-2/s3/aws4_request\u0026X-Amz-Date=20220728T053316Z\u0026X-Amz-SignedHeaders=host\u0026X-Amz-Signature=0c16c754e310e8229f0b5a31f928cc6e432b53ed7d9957dd59b23d4b187c9dfd"
Please notice the character u0026 in response. Normally, after JSON decoding this would be replaced with &. cURL does not have a built-in JSON parser/decoder and it shows raw responses. If this un-parsed raw link is directly utilized it will appear as broken.
Use the “name” parameter to return a custom filename
The name parameter works on most of the API endpoints that return files in output.
For example, the pdf/edit/add API endpoint by default returns the filename of the original file. You can modify the filename by adding a name parameter in the request, e.g "name": "filename_here",.
Response Body:
{
"hash": "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855",
"url": "https://pdf-temp-files.s3.us-west-2.amazonaws.com/MYSLQJEX0Y3SIEW9FMQY2KT0H39XB09A/filename_here?X-Amz-Expires=3600&X-Amz-Security-Token=FwoGZXIvYXdzEN7%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaDPiE4L2emq58D5Nq%2FCKCAdxB1sOgSf7Euq%2FPnwiUfmqfheDr0zAcvZFOVwH12XGuEHgO1QpyuF3rB%2Bnp0%2Fs1Y28ssKQnbSpEA2Kqnqtqd7V8h0FTBmkUTBLNzrFVuygjbMA%2FNP5fYqybQ5bQHrTrH%2FenyjMydpVR7RPhgnrNV7Vc71XsCMJLNw%2BUK1NGp4c4KHgonMrenQYyKKFu5FyKltXsOnGXW3upduOI3qHM2%2BavfkVsmQRCROuabLCMIwTzOB8%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIA4NRRSZPHIQZMGGRJ/20230106/us-west-2/s3/aws4_request&X-Amz-Date=20230106T071940Z&X-Amz-SignedHeaders=host&X-Amz-Signature=67ac6cef6b8bb3aae652e9f942c4667c809e3389016386f3f7f4d6f8f99d1999",
"pageCount": 1,
"error": false,
"status": 200,
"name": "filename_here",
"credits": 21,
"duration": 277
}
PHP - Peer certificate cannot be authenticated#
The Peer certificate cannot be authenticated error appears because SSL certificates or libraries on the computer need to be updated.
To update, run in PHP:
composer update
For more information and other solutions for this issue please explore https://stackoverflow.com/search?q=peer+certificate+cannot+be+authenticated+%5Bphp%5D.
SSL Certificate error unable to get local issuer certificate issue in PHP#
(PHP language): SSL certificate error: unable to get local issuer certificate. To resolve this issue, please try this solution on Stackoverflow.
Salesforce Apex Error 442#
If you attempt to use a file hosted in Salesforce but receive error 442, it could mean that the file url is sending our API a file that is not compatible with the expected file format.
Please refer to this article to get the direct download link: https://salesforce.stackexchange.com/questions/369497/how-to-derive-a-direct-link-to-a-file-from-the-link-to-the-download-page.
If it doesn’t resolve the issue, please contact our support team at support@pdf.co.
Status errors returned by PDF.co#
API returns https status but also returns JSON that includes status parameter indicating error.
Status value |
Description |
|---|---|
|
The request has succeeded |
|
Bad input parameters |
|
Unauthorized |
|
Not enough credits |
|
Forbidden (source file or url is not accessible) |
|
Timeout error. To process large documents or files please use asynchronous mode ( set |
Note
Don’t forget to set x-api-key url param or http header param (preferred) to your API key. Get your API key here.